Московский транспорт перейдет на большие данные. «Большие данные» помогли посчитать туристов Технология big data на транспорте
Спикер: Филипп Кац

Интервьюер: Алексей Карлинский
Мы много раз верили обещаниям фантастов о невероятном будущем, и каждый раз наши надежды разбивались об унылое настоящее. Мы все еще живем на земле, и наши машины не летают по воздуху. «Нас опять обманули!», - думаем мы, и за всеми этими фантазиями в очередной раз упускаем момент, когда будущее по-настоящему наступает.
На этот раз это произошло с появлением Big Data. Мы можем игнорировать их, но отрицать их влияние на нашу жизнь уже не получится. О том, как Big Data незаметно изменили наши города и то, как мы живем в них, рассказывает архитектор и специалист в области Big Data Филипп Кац.
Мультидисциплинарный специалист, архитектор по образованию, Филипп является специалистом по работе с Big Data. Выпускник Казанского архитектурного университета, Института медиа, архитектуры и дизайна «Стрелка», один из основателей проекта «Точка Ветвления». Преподает в Санкт-Петербургском национальном исследовательском университете информационных технологий, механики и оптики и занимается анализом данных для компании Rambler&Co.
Закрыть
Филипп, расскажи, пожалуйста, как технологии Big Data используются в архитектурном проектировании и городском планировании сегодня?
Начнем с того, что четыре года назад, когда я в «Стрелке» учился, в России, по крайней мере, про Big Data никто не знал. В мире о них только-только заговорили. Через год в России уже все про них знали и ими переболели. Мне кажется, это во многом традиционная динамика — когда новая технология поднимается на пьедестал, восхваляется, а потом довольно быстро в отношении нее появляется скептицизм. Технологию сбивают с пьедестала, и после этого они интегрируются в общество в более спокойном режиме.
Если говорить об архитектурной или градостроительной аналитике, то, мне кажется, сегодня это некий компромисс между современными технологиями и традиционным анализом. Например, год назад я помогал своей подруге участвовать в архитектурном конкурсе для студентов в США. Для них сити-менеджер предоставлял GIS-файлы с довольно хорошим описанием данных: транспортные пути, объем этих путей, где появляются лужицы каждый год, где подтопляет каждые пять лет, где блоки с высоким уровнем налогов, где блоки с высоким процентом чернокожего населения. В Соединенных Штатах детализация статистики высокая и данные довольно хорошо сводятся, поэтому даже на уровне конкурсного проекта мы могли какие-то вещи получать в готовом виде. Их не надо было ни собирать, ни анализировать.
Большинство самой полезной аналитики, на мой взгляд, к тому и сводится, что ты какие-то данные берешь как факты и на основе этого проектируешь. И хотя данные могут быть у всех одни и те же, читают и понимают их всё равно абсолютно по-разному.

Google утверждает, что их самоуправляемые автомобили могут уменьшить количество автокатастроф и помогут более эффективно использовать топливо и пространство на дорогах / фото: Google.com
Как ты использовал технологии Big Data в своей практике?
Мы долгое время делали проект« Точка Ветвления» с моими коллегами Эдиком Хайманом и Сашей Болдыревой — пытались как-то обсуждать и развивать цифровое проектирование и, естественно, тогда нашей общей постулируемой мечтой и конечной целью являлось проектирование на основе параметров. При этом наш предел мечтаний был именно в том, чтобы на основе какого-то хитрого кода найти новые формальные решения, которые отвечали бы нашим требованиям, но форма результата при этом оказалась бы не та, которую мы закладывали, а какая-то неожиданная — красивая.
Аналитика — это вид искусства, где в каждом конкретном случае алгоритм работы с данными — это картина
В зрелом возрасте проекта мы все понимали, что эта мечта не то чтобы была недостижима, а скорее была спорна мысль о том, что здание стоит полностью проектировать только лишь на основе данных. Это скорее то, к чему нужно стремиться, но понимать, что ты туда никогда не дойдешь.
Тут возникает важный для меня диалектический момент. Допустим, мы делаем алгоритм и понимаем, что, в первую очередь, из-за генетических требований он требует довольно простых, но все-таки формальных параметров. И в сложной системе, а здание или район — это сложная система, сразу появляется множество таких параметров, которые нужно привести к единому знаменателю. Тебе всегда нужен первичный формальный жест, какая-то форма: цилиндр или параллелепипед, пирамидки и так далее.
Если мы посмотрим на работы Захи Хадид, то в основе проекта всегда лежит какой-то изящный формальный жест. Он может потом видоизменяться цифровым образом, но всегда остается в основе всего и принадлежит перу автора. Генетический алгоритм может потом выбрать лучший из получившихся вариантов, но изобрести их никогда не сможет.
То есть, в основе проектирования всегда будет человеческая воля. Как в таком случае будет меняться степень вовлеченности человека в проектирование с развитием Big Data?
В будущем я вижу некую аналитическую машину — большой и сложный квантовый компьютер, например, или телепатов и парапсихологов, погруженных в депривационные камеры, которые что-то предсказывают или подсказывают, на что стоит обратить внимание.
Я думаю, человек никогда не будет выдавлен из процесса. Все эти вещи(методы анализа Big Data) называются алгоритмами помощи в принятии решений, и их суть сводится к тому, чтобы максимально эффективно вытаскивать аномалии в динамиках процессов и максимально уменьшить процент технического труда на одного человека. Аналитик должен быть экспертом в области работы с ними, и алгоритмы могут ему на блюдечке принести все, кроме, собственно, решения. Конечно, существует технический порог вхождения в эту дисциплину, но сама аналитика — это вид искусства, где алгоритм работы с данными — это картина. Шедевр.

Дроны, оборудованные камерой, могут самостоятельно патрулировать заданную территорию и переносить изображения в информационный центр в реальном времени / фото: Kevin Baird / Flickr.com
Big Data не могут охватить всей информации. Как работать с тем, что не учитывается при анализе Big Data?
Действительно, аналитиков часто критикуют за то, что мы описываем только тех, кто подключен к интернету, а те, кто не подключен к интернету, выбиваются из анализа. Это абсолютная правда, но тут есть своя логика защиты. Говоря цинично, если мы не знаем проблемы бабушки, которая стесняется написать в интернет, потому что она там не привыкла, то мы можем ее проблемы игнорировать, просто потому что если мы будем использовать такой подход, то либо бабушка, либо ее внук за нее, в конце концов, напишут.
Другая проблема кроется в том, что любая технология сбора или хранения данных — это всегда первый фактор ошибки. При этом отследить всю мультифакторность — почему люди сыграли так, а не иначе — невозможно в принципе. На первых порах Big Data не дают ответа. Они позволяют задать серьезные вопросы.
Как возможность задавать вопросы по-новому меняет наше представление о городе?
Эдуард Хайман когда-то придумал термин« плагополис». Идея заключается в том, что современный город становится все более проактивным и динамичным. Сегодня это некая среда со своими потоками, движениями, где жидкость, которая переливается в сосудах, все время саморегулируется. При этом схватить точку и зафиксировать ее ты можешь только очень условно. Она мгновенно изменится сама и поменяет другие точки вокруг себя. Для меня эта идея — довольно прикладная вещь, с которой можно работать. Сейчас становится ясно, что мы больше не можем воспринимать город как что-то механистичное.
Эту идею принимают в российском градостроительстве?
На уровне градостроительства в таком русском понимании это неочевидно. Мы, так или иначе, начинаем с рисования дорожек, улиц, и мы верим, что так оно в итоге и будет. В лучшем случае мы начинаем думать, что надо бы проверить, как это сделать правильно, и тогда это либо будет так, как мы нарисуем, либо люди сами все потом переделают.
Big Data не дают ответа. Они позволяют задать серьезные вопросы
Вообще, голословные утверждения на основе стереотипов и абстрактных идей сегодня сильно раздражают. Причем архитекторы и градостроители в первую очередь с ума сводят. Они просто говорят что« пешеходы лучше, чем автомобилисты» или что« креативный бизнес превратит индустриальный парк в рай земной». Хотелось бы, чтобы за любыми такими вещами проходил базовый расчет, потому что может быть так, а может быть и не так, и в большинстве случаев бывает как-то не так.
Как тогда Big Data могут помочь нам лучше понять город?
Город — это всегда слон из сказки про слепых, которые пытаются описать его на ощупь. Мы всегда работаем так же — кто-то за попу хватает, кто-то за ухо, кто-то за хобот. И каждый при этом рассказывает, что видит слона. В нашем случае все мы еще и считаем, что мы зрячие и знаем, что такое город.
Big Data защищают нас от того, чтобы пощупать только в одном месте, дают нам возможность примерно представлять общую форму слона и понимать, что мы трогаем за примерно вот это место, но есть и другие. Я получаю огромные отчеты по городу и всегда могу в какие-то конкретные десять строк данных залезть, посмотреть и спросить: почему так? Обычно это становится началом для какого-то расследования, исследования, истории.

GIS data в сочетании с альгоритмами моделирования в пространстве помогают предсказывать уровень изоляции на выбранной территории / фото: Trevor Patt / Flickr.com
Эти размышления, вдохновленные Big Data, как-то впоследствии выражаются в реальных проектах?
Существует так называемый метод« городской акупунктуры». Суть его заключается в том, что в городе ищутся как бы болевые узлы, и в этих маленьких узелках — в пространствах максимум в квартал, а лучше в одно здание, или даже на какой-то маленькой площадочке между зданиями — делается какое-то изменение. Из-за размеров бюджета оно совершенно микроскопическое, а изменения для города в целом, если правильно рассчитать эти узлы, — происходят огромные.
Хотя« городская акупунктура» сегодня — это скорее умозрительный проект, уже сейчас существуют умные пространственные решения, со светофорами в единой системе, например. Они, вкупе с умными дорогами, позволяют менять пространство, и это может дать неожиданные выхлопы. Ещё сегодня происходит роботизация индустрий, и это тоже добавляет ценности. Если сейчас дроны начнут перевозить грузы, то городская логистика смерджится(от англ. to merge — «сливаться» — А.К.) — и там цифры, и тут цифры. С этим будет работать, определенно, гораздо легче, чем с живыми дальнобойщиками.
Технология, которой я сейчас вдохновляюсь, и я надеюсь, из этого произойдет что-то архитектурное, — это новый проект Amazon, когда стоит умная колонка в центре дома, которая слушает все твои вопросы и на них отвечает. Примерно как Siri, только в доме. Эта технология, возможно, поменяет ощущение пространства города сильнее, чем любой алгоритм.
То есть город будет все больше полагаться на программное обеспечение?
Именно. Сейчас I/O и различные интерфейсы получения информации человеком многое меняют институционально. С моей точки зрения, сервис по вызову дешевого такси меняет в моей жизни гораздо больше, чем 90 процентов градостроительных решений. Такси многое меняют в моем восприятии города. Несмотря на весь предыдущий опыт, с появлением Яндекс. Такси и конкуренцией такси-сервисов получилось, что и таксисты у нас вежливые, и деньги конкретные, и реагируют они быстро — совершенно не так, как в каком-нибудь Нью-Йорке.
Сервис по вызову дешевого такси меняет в моей жизни гораздо больше, чем 90 процентов градостроительных решений
Мне кажется, самый важный сервис, который мог бы словить огромную прибыль от уберификации, — это проституция. Гипотетический пользователь стесняется, и, может быть, множество людей поэтому и не пользуются услугами проституток, — это им кажется чем-то опасным, страшным и непонятным. Сидя у себя в телефоне — им, безусловно, было бы гораздо проще. Конечно, это сразу бы отобрало хлеб у сутенеров и совершенно изменило бы бизнес. Просто колоссально! Я думаю, в какой-нибудь либеральной стране в скором времени так и произойдет.
Как ты думаешь, люди в будущем смогут работать с технологиями Big Data персонально?
Я думаю, все к этому идет. Технологическая сложность будет возрастать, и это понятно, а практически — мы будем учиться это как-то правильно упаковывать. Слик-интерфейсы (от англ. sleek — тонкий, изящный — А.К.) сегодня в какой-то степени упрощают наше восприятие того, как все происходит. Вот кнопочка, вот пипочка — и всё. Сегодня чем больше ты можешь спрятать от обычного человека, не потеряв при этом функцию, тем лучше, потому что люди немного напуганы всей этой сложностью. Хотя известной технологии, как в «Особом мнении», не появилось, но ощущенчески фильм очень правильно описывает то, что сейчас будет происходить.
Что это будет? Как ты думаешь, с чем предстоит столкнуться большим данным в ближайшем будущем?
Они появились как некая модная тема и сейчас потихоньку притухают, потому что самые очевидные вещи уже сделаны. Дальше надо будет технические механизмы в методике прорабатывать — не в романтическом, а утилитарном виде. Через пять лет, я уверен, появится довольно хорошо оплачиваемая и, возможно, довольно скучная должность какого-нибудь цифрового аналитика в мэрии, при министерствах и бизнесах.
При этом у Big Data есть некая болезнь. Есть люди, которые понимают, что они делают, и есть люди, кормящиеся с этого, которые не очень понимают, как работают Big Data. Дырка между профессиональными технологами и людьми, понимающими, зачем это все может быть, всегда существует в любом бизнесе, в любой науке, и это, безусловно, некая проблема. Люди, которые знают технологическую часть и экспериментируют с новыми решениями, редко делают реально полезные вещи, а люди, которые знают, как можно применить эти разработки, также не могут создать качественного продукта в одиночку. Поэтому единственный путь к развитию при работе с Big Data — это найти новые способы взаимодействия между специалистами.
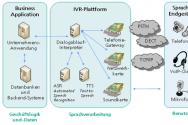
Москва – огромный мегаполис с 11 979 529 жителей, по данным переписи населения 2013 года. Каждый из них ездит на работу, пользуется мобильным телефоном (а то и не одним), спускается в метро, стоит в пробках. За всем этим следят городские службы, государственные органы, частные компании, предоставляющие различные сервисы. Тысячи видеокамер, сотни тысяч датчиков, мониторов, которые контролируют жизнь города, миллионы мобильных телефонов, 3G/4G-модемов. А все вместе это миллиарды источников данных, обрабатывая которые можно получить информацию для дальнейшего планирования развития города, управления его транспортными потоками, обеспечения безопасности мегаполиса. Одним из немногих инструментов, способных справиться с обработкой такого количества информации, являются решения класса Big Data. Для начала рассмотрим, где они могут быть использованы.
Плотность проживания населения и данные о перемещении жителей
Основным инструментом определения численности и структуры населения, его распределения по местности на текущий момент является перепись. Основной недостаток переписи – стоимость её проведения и отсутствие данных о движении жителей. Источником информации для переписи служат сами жители, опрос которых проводится по месту их проживания.
Какие преимущества может предоставить использование решений Big Data? Для ответа на данный вопрос сначала определим, какие данные нам необходимы:
- где ночуют и работают жители;
- откуда и куда они ездят в будни и выходные;
- каким транспортом пользуются москвичи и гости столицы;
- откуда приезжают в город и зачем.
Для сбора этой информации нам в первую очередь необходимо определиться с источником данных и методом их анализа. Для определения местоположения жителя самым оптимальным является использование данных о местоположении его сотового телефона (он всегда с собой). Как это сделать?
Можно получить:
- данные от сотовых операторов о местоположении телефонного аппарата;
- данные от специализированных сервисов (таких, как “Яндекс.Пробки”);
- данные от мобильных приложений со встроенным функционалом определения местоположения, предоставляемых городом для удобства жителей.
Для анализа полученной информации могут быть использованы различные алгоритмы в зависимости от источника, формата, способа их предоставления. Но вот основные положения.
Определение места, где ночуют жители и где работают, может быть получено путем анализа данных о перемещении и совершённых действиях. Например, периодическое отсутствие звонков с 22:00 до 7:00 и отсутствие перемещения покажет, где человек живет, а отсутствие перемещений в рабочие часы – где тот же человек работает, причем одним из критериев, повышающих точность, будет наличие активности телефонного аппарата абонента в данном местоположении. Здесь же можно будет определить, как часто человек перемещается в рабочее время, сколько людей в городе занимают должности, связанные с постоянным передвижением (курьеры, водители и другие профессии).
Определение направления перемещений жителей осуществляется аналогично, по тем же данным о перемещении абонентов сотовой связи, и позволяет выделить основные потоки перемещений местных жителей, приезжих, трудовых мигрантов, собрать статистику перемещений по районам и направлениям, узнать, как часто жители и гости посещают магазины, культурные мероприятия, городские достопримечательности, а также насколько популярны те или иные места в городе.
Отслеживая скорость перемещения и посещённые места, можно выделить, каким транспортом пользуется человек: автомобиль, метро, наземный общественный транспорт, междугородный транспорт.
Анализ работы городской инфраструктуры и обеспечение безопасности населения
Большое количество светофоров, систем управления городским движением, систем видеорегистрации событий (камеры наблюдения), контроль общественного транспорта в рамках города с населением более миллиона человек требует скоординированного подхода в управлении и централизации данных. Одной из проблем, выявленных в свое время при внедрении систем общегородского видеонаблюдения, стала невозможность контроля происходящих событий (например, с целью выявления неправомерных действий) силами оперативных дежурных. Учитывая текущие возможности современных технологий, становится возможным создание единых распределённых систем, обеспечивающих как распознавание событий по различным источникам (системы регулирования движения, камеры наблюдения и прочие), так и их аналитику с целью оперативной реакции: вызов полиции, сотрудников ремонтных организаций, иных оперативных служб города. Другим применением решений Big Data является распределенное и длительное хранение собранной информации, осуществление поиска необходимых данных и связанных с ними событий. Чем было вызвано то или иное изменение ситуации в городе, какие события ему предшествовали, на кого они повлияли – вот маленькая часть вопросов, на которые позволяют ответить «большие данные».
Сопоставление данных
Одним из ключевых моментов происходящих событий является определение характеристик объектов, в них участвующих. Для сбора данных могут быть использованы совершенно различные источники: например, для данных, полученных от оператора сотовой связи, – характеристики физического лица, на которого зарегистрирована сим-карта, для систем наблюдения – сведения от систем распознавания лиц, ведомственные базы данных. Одним из ключевых моментов является возможность анонимизации информации, исключения персональных составляющих при передаче данных от различных владельцев, источников.
Основные проблемы
И всё же во всём этом есть ложка дегтя. Основной проблемой всех интеграционных решений, особенно если обмен данными осуществляется между разными ведомствами, организациями, являются законодательные ограничения, которые не позволяют предоставлять данные в том виде, в котором они существуют. Как следствие – требуется предварительная их обработка на стороне владельца.
Итого
Подводя итог, хотелось бы отметить, что современные технологии обработки “больших данных” позволяют предоставить городу значительно больше, чем существующие ИТ-сервисы. При этом не требуется обновлять существующую инфраструктуру, так как могут быть использованы те источники данных, которые есть в настоящий момент.
С помощью решений класса Big Data можно повысить удобство жителей города и его гостей, уменьшить количество пробок не за счёт ограничений на въезд в город, а путём управления транспортными потоками, снизить количество преступлений благодаря оперативной реакции, повысить качество предоставления городских услуг вследствие их оперативного и автоматического контроля.
Данные стали важным активом, они представляют немалую ценность сами по себе. При правильном подходе к определению владельца и внимательном построении доступа к ним они могут приносить прибыль всем участникам перевозочного процесса. Но могут стать и яблоком раздора, - пишет журнал .
«Данные превратились в актив. Данные сегодня – это золото и нефть XXI века. Тот, кто быстрее с ними научится работать, обрабатывать, кластеризировать, делать из них продукты, которые повышают добавленную стоимость, тот и будет впереди», – убеждал своих слушателей Михаил Мишустин, глава Федеральной налоговой службы, на сессии «Цифровая трансформация и качество жизни. Взгляд из регионов», прошедшей в рамках Российского инвестиционного форума в Сочи. Он ведёт речь о так называемых больших данных – и кому как не главе ФНС, где собраны данные о доходах и имуществе миллионов россиян, понимать всю их ценность? Но на самом деле чиновник лишь повторил фразу, которую сейчас можно услышать на сотнях форумов по всему миру от руководителей тысяч компаний, в том числе глобальных. И первый же вопрос, который возникает: раз большие данные стали ценным активом, значит, должны появиться правила, которые опишут, как с ними обращаться, кто ими владеет, можно ли и по какой цене эти данные купить?
Технология больших данных подразумевает наличие трёх элементов: огромных массивов данных, вычислительных мощностей для очень быстрой обработки этих данных и специальных математических моделей, позволяющих сравнивать заранее определённые параметры, доступ к которым раньше был запрещён. Это позволяет выявлять новые, очень часто неочевидные связи и закономерности и уже на основе их принимать управленческие решения и извлекать прибыль (или как вариант – решать общественно важные задачи).
Для того чтобы извлекать из больших данных пользу, должны были дозреть технологии. Совсем недавно в распоряжении компаний появились вычислительные мощности и алгоритмы, которые в состоянии быстро обрабатывать огромные массивы данных в режиме реального времени, дата-центры, где эти данные можно хранить, развивается так называемый Интернет вещей, который позволяет в режиме реального времени получать данные от оборудования и различных устройств, улучшаются характеристики и падает цена датчиков, которые используются для сбора данных.
Алексей Федосеев, руководитель департамента сервисной поддержки заказчиков «Сименс Мобильность», так определяет границу, с которой данные могут считаться большими: «1 млн измерений, так называемых дата-пойнтов. С этого момента мы можем реализовывать аналитические модели, которые основываются на подходе Big Data».
Пионерами стали авиастроители. Ценность больших данных, на основе которых можно предсказывать неисправности и отказы оборудования, в этой отрасли особенно велика. Например, сейчас Boeing 737 с двумя двигателями за шесть часов полёта передаёт 240 тыс. терабайт данных (объём данных на бумажных носителях в Ленинской библиотеке больше, но ненамного – примерно в 84 раза). Речь идёт о снятии за полёт нескольких сотен тысяч параметров, хотя предыдущие поколения самолётов собирали их всего несколько сотен.
В прошлом году глава горнодобывающей компании Tinto (в её парке данные снимаются с беспилотных самосвалов, буровых на карьерах, локомотивов и в порту) рассказал, что Центральный пункт управления в городе Перт получает 2,4 терабайта данных каждую минуту (приблизительно 3,5 тыс. терабайт в сутки).
Андрей Бородин, главный инженер проекта в Проектном конструкторско-технологическом бюро Центр цифровых технологий Департамента информатизации ОАО «РЖД», говорит, что, с точки зрения профессионалов, данные бывают горячие (то есть попадающие в обработку сразу, в режиме реального времени), тёплые и холодные (неиспользуемые, но оставленные для хранения).
«И даже сырые данные небезосновательно рассматриваются многими компаниями как актив, способный приносить ценность, даже если компании сейчас не могут ими воспользоваться, – сделать предиктивные модели или системы реагирования в режиме реального времени», – говорит Олег Пятаков, руководитель направления по инвестиционному анализу компании «2050. digital». Он уверен, что генерировать данные ради данных контрпродуктивно как минимум в ближайшей перспективе: «Нужна возможность связать данные между собой (идентификаторы устройств/пользователей, временные метки), хотя бы минимальная значимость данных для тех целевых параметров, которые пытаемся оптимизировать, умение выработать управляющее воздействие. Ведь в традиционных (старых) управленческих системах нормой была ситуация, когда более 95% собираемых данных в силу разных причин не использовались для принятия решения».
«РЖД» стали одной из первых компаний России, начавших процесс цифровой трансформации. И с технологией больших данных холдинг, конечно, тоже работает. Естественно, первая область для применения их очевидна – регулярный сбор данных с подвижного состава и инфраструктуры при помощи Интернета вещей.
В «Сименс Мобильность», который является стратегическим партнёром «РЖД» в этой области, проводится чёткое различение двух понятий – данных и информации. Данные, которые генерируются подвижным составом, инфраструктурой, по словам Алексея Федосеева, принадлежат эксплуатирующей организации: «Как только мы поставили технические системы компании Deutsche Bahn или ОАО «РЖД», данные принадлежат им».
Затем в рамках сервисных контрактов, в рамках отдельных контрактов на обработку этих данных они преобразовываются в полезную информацию. Например, поезда «Ласточка», которые эксплуатируются на МЦК, генерируют диагностические сообщения о техническом состоянии отдельных подсистем электропоезда. Эти данные агрегируются и по защищённому каналу передаются на сервер на территории РФ. И только потом, говорит Алексей Федосеев, в Центре анализа и обработки данных, созданном совместно ОАО «РЖД» и «Сименс» в феврале 2017 года, эти агрегированные данные преобразуются в полезную информацию.
Сотрудники центра используют аналитические модели, которые на базе полученных технических параметров позволяют реализовать концепцию предиктивного техобслуживания, прогнозировать отказы критически важных узлов подвижного состава, рассказывает эксперт. Пример – обработка данных, полученных с системы тягового привода. Но не только. Контролируется, например, и система пассажирских дверей. При движении в режиме городской электрички работа пассажирской двери может влиять на время нахождения поезда на станции, сбои и отказы в их работе могут влиять на нарушение графиков движения. К этой информации через компьютеризированную систему технического обслуживания Cormap имеют доступ сотрудники отдела ремонта Дирекции скоростного сообщения ОАО «РЖД». Система открыта, на её основе принимаются решения о выдаче поездов на линию.
Модели предиктивной аналитики по эксплуатации высокоскоростных поездов, поставляемых «Сименс» для немецких, испанских, российских, турецких железных дорог, а также компании Eurostar, совершенствуются на протяжении последних трёх-четырёх лет. Чем больше данных обработано, тем точнее модели функционируют. Результатом становится повышение технической готовности поездов. Например, работа Центра удалённого мониторинга компании «Сименс» по поездам Velaro в Испании началась немного раньше, чем с «Сапсанами» в России. Модели позволяют прогнозировать отказы тяговых двигателей за пять–семь дней, что привело к практически полному исключению возможности нарушения графика движения по причине снижения тяги. В результате компания RENFE продемонстрировала готовность компенсировать 100% стоимости билета пассажирам при опоздании поезда более чем на 15 минут на линии Мадрид – Барселона. Реакция пассажиров не заставила себя долго ждать: доля железнодорожных перевозок в пассажирообороте на данном направлении выросла с 20 до 61%, а авиаперевозок снизилась с 80 до 39%.
Если брать российский опыт по внедрению аналогичных моделей предиктивной диагностики поездов «Сапсан», то, по словам Алексея Федосеева, положительные эффекты очевидны: на линии Москва – Санкт-Петербург парк поездов «Сапсан» прошёл уже более 7 млн км без опозданий по причине технических отказов, которые превышают 5 минут (это один из параметров, его компания использует, чтобы оценить уровень надёжности).
Важной частью работы с большими данными стало создание так называемой доверенной среды – она предназначена для безопасного использования данных, исключения неправомерного доступа к ней. Например, «Доверенная среда локомотивного комплекса» строится для доступа к данным, которые будут генерироваться локомотивами, потребителями этих данных – сотрудниками холдинга «РЖД», сервисных компаний, производителями подвижного состава и производителями компонентов.
Не всегда взаимоотношения основаны на партнёрской основе. В этом случае возможно противостояние сторон, участвующих в предоставлении и обработке данных. Как это может происходить, демонстрирует история, которая прямо сейчас развивается с датской компанией Maersk, лидером океанских перевозок. Ещё в 2014 году компания решила, что будет цифровать свой бизнес океанских перевозок. Maersk тогда сообщила, что простая отправка морем охлаждённых фруктов из Восточной Африки в Европу проходит по цепочке из 30 людей и организаций и требует около 200 актов взаимодействия (передача документов, общение) между ними, а 20% затрат на доставку партии товара приходится на обработку, передачу документов и администрирование процесса. Maersk собиралась радикально снизить затраты в этой сфере, где серьёзных изменений не происходило уже 60 лет.
В 2016 году она определилась с технологией и партнёром, начала сотрудничество с компаний IBM как носителем продвинутых знаний в блокчейне. Блокчейн-систему умных контрактов, получившую название TradeLens, начали тестировать в 2017 году. В январе 2018 года Maersk и IBM объявили о создании совместного предприятия. Работали с партнёрами, чтобы понять, как ускорить передачу информации и снизить количество ошибок. Было объявлено, что к концу 2018 года будет запущена полноценная коммерческая версия TradeLens. Уже к середине 2018 года система содержала данные о 154 млн событий (даты прибытия судов, отчёты об отправке и прибытии контейнеров, таможенные разрешения, коммерческие счета и коносаменты, то есть документы о принятии груза перевозчиком от грузоотправителя), их количество прирастало на 1 млн каждый день – в общем, TradeLens была готова к полноценной эксплуатации.
На тестовой стадии к системе присоединились 92 участника: судовладельцы, океанские перевозчики, грузоотправители, порты (например, очень крупный порт Роттердама, через который проходит до 2/3 океанских грузов для Европы) и таможни. Но в то же время, как заканчивалось тестирование, стало известно, что другие океанские перевозчики категорически отказались подключаться к TradeLens. А без информации этих игроков исключено полноценное использование системы.
Похоже, для Maersk такое сопротивление стало неожиданностью. В середине ноябре датская компания приняла предложение конкурентов по первой шестёрке (MSC, CMA CGM, Hapag-Lloydand и Ocean Network Express) войти в некоммерческое объединение, которое займётся разработкой новых стандартов для обмена информацией в отрасли. Андре Симха, CIO компании MSC, океанского перевозчика № 2, заявил журналистам, что его компания с удовольствием присоединится к TradeLens, если компания станет более открытой. И вообще MSC гораздо больше нравится идея работать через некоммерческое объединение, ведь, несмотря на обещания равного доступа к информации, все интеллектуальные права на TradeLens разделены между IBM и Maersk. Перевозчикам не понравилась перспектива отдавать свои данные в систему, притом что зарабатывать на них будет их главный конкурент. Олег Пятаков всё же считает, что Maersk пошёл по правильному пути и в конце концов будут побеждать проприетарные решения мощных компаний, а открытые стандарты без участия сильных игроков будут уступать позиции. Но Maersk придётся побороться за владение таким ценным активом, как данные. В ноябре было объявлено о создании конкурирующей с TradeLens системы.
«Мегафон» разработал и представил в пользование «дочкам» РЖД тестовую версию сервиса для анализа пассажироперевозок, основанную на «больших данных», сообщает РБК со ссылкой на представителя оператора Максима Мотина. Инструмент помогает определить размер и подробные характеристики рынка перевозок, а также долю транспортной компании на нем в режиме, близком к реальному времени.
Сейчас идет подготовительная работа по внедрению системы для анализа Big Data, подтвердил начальник отдела ERP-систем (системы для планирования ресурсов предприятия) управления информационных технологий ФПК РЖД Олег Емченко. «В какой-то конкретный проект это может воплотиться только в 2016 году», - сказал Емченко.
Сервис геоаналитики «Мегафон» запустил еще в 2013 году, первоначальной целью было прогнозирование нагрузок на сеть. С его помощью можно оценить точный объем пассажиропотока, получить информацию о маршрутах (кто, когда, откуда и куда направляется), раскладку по видам транспорта. Сервис также оценивает платежеспособность пассажиров и характер путешествий (деловые поездки, туризм, личные нужды). Все данные обезличены.

Можно анализировать более 10 тысяч событий в секунду по более чем тысячи параметрам, уточнил директор «Мегафона» по сегментному маркетингу и клиентской аналитике Роман Постников. За три года накоплено уже более 5 петабайт информации - объем, сопоставимый с более чем 30 миллиардов фотографий на Facebook. Постников уверяет, что под каждого клиента определяется свой список параметров для анализа, то есть фактически речь идет об универсальном облачном решении, которым могут пользоваться абсолютно разные по типу заказчики, нуждающиеся в анализе больших массивов данных.
В «Мегафоне» подсчитали, что транспортные компании в России тратят на исследования пассажиропотоков более 1,2 миллиарда рублей ежегодно. «При этом сами компании могут собирать лишь часть доступных им данных, а наш сервис дает возможность увидеть всю картину рынка в целом», - утверждает Постников. Даже если благодаря внедрению сервиса перевозчик сможет увеличить свою долю на общем рынке пассажироперевозок на 1,5–2%, то это миллиарды рублей, говорит он.
Решения Big Data можно применять также для управления городской инфраструктурой. Экспертный центр электронного государства, правительство Москвы собирается заключить контракт, в рамках которого город в течение двух лет будет получать агрегированные обезличенные геопространственные данные пользователей местных операторов связи в 11 различных разрезах. Потребителями этой информации станут ГУП «НИ и ПИ Генплана Москвы», департамент транспорта и развития дорожно-транспортной инфраструктуры, департамент культуры и другие столичные ведомства.